
The Roadblocks in Prometheus Scaling: Identifying and Tackling Key Issues
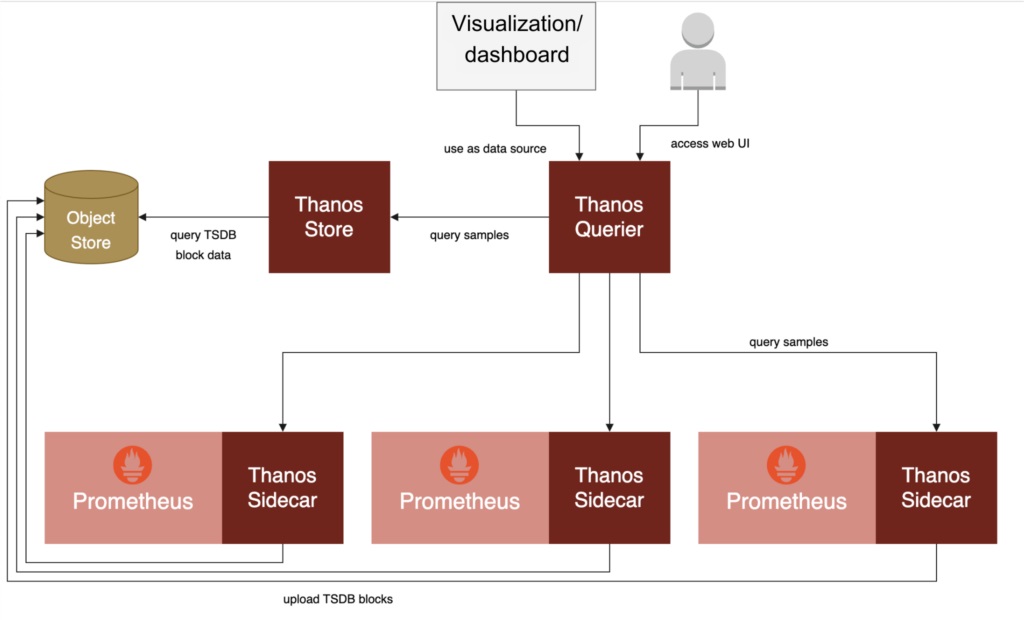
Scaling Prometheus to meet the demands of a growing infrastructure is a commendable endeavor. However, along this journey, Prometheus scaling challenges may arise, hindering your system monitoring efforts. In this article, we will explore the roadblocks that can impede Prometheus scaling and provide insights into effectively addressing these key issues.
Identifying the Prometheus Scaling Challenges
To successfully tackle Prometheus scaling challenges, it’s essential to first identify them. These challenges can manifest in various forms, including:
- Increased Resource Consumption
As the number of targets and metrics grows, Prometheus servers may experience higher resource consumption, leading to performance bottlenecks.
- Slower Query Times
Large volumes of data can result in slower query times, making it challenging to retrieve critical insights promptly.
- Data Retention Management
Balancing the retention of historical data for analysis while avoiding overloading Prometheus servers can be complex.
- High Availability
Ensuring high availability and fault tolerance is crucial, especially in mission-critical environments.
Overcoming the Roadblocks
Now that we’ve identified the challenges, let’s explore strategies to overcome these roadblocks in Prometheus scaling.
- Horizontal Scaling with Prometheus Federation
Prometheus Federation is a powerful approach to distributing the workload and addressing increased resource consumption. By deploying federated Prometheus instances across your infrastructure, you can offload the primary Prometheus server, enhancing scalability and fault tolerance.
- Efficient Data Retention Strategies
Effective data retention is critical to managing Prometheus scaling challenges. Utilize Prometheus’s built-in retention policies and rules to define how long data should be stored. Implement tiered storage solutions to archive older data, reducing the load on your Prometheus servers.
- Load Balancing for High Availability
Load balancing is a key component in achieving high availability and ensuring that no single Prometheus server becomes a bottleneck. Implement load balancers to evenly distribute incoming requests among multiple Prometheus instances, providing redundancy and fault tolerance.
- Resource Optimization and Auto-scaling
Regularly monitor resource utilization on your Prometheus servers and adjust resource limits accordingly. Leverage container orchestration platforms like Kubernetes to automate resource management and enable auto-scaling based on workload demands.
Building a Resilient Prometheus Scaling Strategy
To navigate the roadblocks in Prometheus scaling effectively, it’s crucial to build a resilient strategy tailored to your infrastructure’s unique needs. Keep in mind that the journey to scale Prometheus is an ongoing one, as your infrastructure continues to evolve.
By proactively identifying and addressing Prometheus scaling challenges through horizontal scaling, efficient data retention, load balancing, and resource optimization, you can ensure that your Prometheus monitoring system remains robust and capable of meeting the demands of your expanding infrastructure.
Prometheus scaling may present roadblocks, but with the right approach and strategies in place, you can overcome these challenges and maintain a highly effective system monitoring solution. Stay tuned for more articles in this series, each providing fresh insights into Prometheus and its ability to conquer the complexities of modern system monitoring.







